


 Sentiment analysis (also known as opinion mining) refers to the use of natural language processing (NLP), text analysis and computational linguistics to identify and extract subjective information from the source materials. Generally speaking, sentiment analysis aims to determine the attitude of a writer or a speaker with respect to a specific topic or the overall contextual polarity of a document.
Sentiment analysis (also known as opinion mining) refers to the use of natural language processing (NLP), text analysis and computational linguistics to identify and extract subjective information from the source materials. Generally speaking, sentiment analysis aims to determine the attitude of a writer or a speaker with respect to a specific topic or the overall contextual polarity of a document.
Globally, business enterprises can leverage opinion polarity and sentiment topic recognition to gain deeper understanding of the drivers and the overall scope. Subsequently, these insights can advance competitive intelligence and improve customer service, thereby creating a better brand image and providing a competitive edge. Let’s begin by first understanding the adoption of sentiment analysis across industries.
Sentiment Analysis Adoption
Here are some of the top industry verticals, where sentiment analysis is being widely utilized and yielding positive results.
E-Commerce
The e-commerce industry is benefitting greatly by utilizing sentiment analysis. Generally, on e-commerce portals, buyers often express their opinions in the form of comments (positive or negative) for the products they have purchased, making this a huge data trove for sentiment analysis. Correspondingly, analysis of such opinion-related data (comments) can provide deep-insights to the key stakeholders. A thorough sentiment analysis reveals deep-insights on the product, quality and performance. Additional insights that can be extracted using sentiment analysis include.
- Insights on competitors
- Feedback on newly launched products
- Influencing factors affecting other customer decisions
- Company news and trends
Financial Domain
Sentiment analysis is widely used across the financial domain for trading and investing. Notably, financial analysts and traders monitor/analyze social networks (i.e. utilizing StockTwits) to quickly identify the trending stocks and fluctuations in the stock markets, which enable them to react swiftly to any major changes in the stock market.
Aviation Sector
In case of the aviation sector, sentiment analysis can help aviation companies detect sentiment polarity and sentiment topics by making use of data (text) and examining the reputation of airlines by computing their Airline Quality Rating (AQR). In this blog, we have considered use case of leading US airliners (Delta, JetBlue and United Airlines) to demonstrate the fundamentals of sentiment analysis.
By and large, social media plays a significant role in sentiment analysis. Here is a comprehensive list of social media websites/platforms, which can be used for sentiment analysis to identify customer likes, dislikes, opinions, feedback, etc.
- YouTube
- Google+
- SlideShare
- iTunes
- Quora
- Blogs
In this blog, we have considered the twitter social media platform to find out how tweets from the twitter feed can be utilized to perform sentiment analysis. As mentioned earlier, we performed sentiment analysis on three leading airlines and R programming language has been extensively used to perform this analysis.
Sentiment Analysis Approach
The approach followed here is to count the positive and negative words in each tweet and assign a sentiment score. This way, we can ascertain how positive or negative a tweet is. Nevertheless, there are multiple ways to calculate such scores; here is one formula to perform such calculations.
[java]Score = Number of positive words - Number of negative words If Score > 0, means that the tweet has 'positive sentiment' If Score < 0, means that the tweet has 'negative sentiment' If Score = 0, means that the tweet has 'neutral sentiment'[/java]
To find out the list of positive and negative words, an opinion lexicon (English language) can be utilized.
Extracting and Analyzing Tweets
TwitterR offers an easy way to extract tweets containing a given hashtag, word or term from a user’s account or public tweets. However, before loading twitterR library and using its functions, developers should create an app on dev.twitter.com and then run the following code, which is written in the R programming language.
Setting Authorization to Extract Tweets
Run the following code in the R Studio to set authorization to extract tweets.
[java]reqURL <- "https://api.twitter.com/oauth/request_token" accessURL <- "http://api.twitter.com/oauth/access_token" authURL <- "http://api.twitter.com/oauth/authorize" api_key <- "yourconsumerkey" api_secret <- "yourconsumersecret" access_token <- "consumeraccess token" access_token_secret <- "consumer access secret token" setup_twitter_oauth(api_key,api_secret,access_token,access_token_secret)[/java]
Required Libraries
Here is the code to load required libraries.
[java]library(twitteR) ### for fetching the tweets library(plyr) ## for breaking the data into manageable pieces library(ROAuth) # for R authentication library(stringr) # for string processing library(ggplot2) # for plotting the results[/java]
Importing Files
Developers have to import files containing a dictionary of positive and negative words. Likewise, text files containing positive and negative sentiments can be imported using the below code. These files can be downloaded using the Google search engine.
[java]posText <- read.delim("…/positive-words.txt", header=FALSE, stringsAsFactors=FALSE)
posText <- posText$V1
posText <- unlist(lapply(posText, function(x) { str_split(x, "\n") }))
negText <- read.delim("…/negative-words.txt", header=FALSE, stringsAsFactors=FALSE)
negText <- negText$V1
negText <- unlist(lapply(negText, function(x) { str_split(x, "\n") }))
pos.words = c(posText, 'upgrade')
neg.words = c(negText, 'wtf', 'wait', 'waiting','epicfail', 'mechanical')[/java]
Extracting Tweets with Hashtags
To demonstrate sentiment analysis, we analyzed tweets relating to Delta, JetBlue and United Airlines. In order to extract specific tweets relating to these airlines, developers should query twitter for tweets with the hashtag Delta, JetBlue and United.
[java]delta_tweets = searchTwitter('@delta', n=5000)
jetblue_tweets = searchTwitter('@jetblue', n=5000)
united_tweets = searchTwitter('@united', n=5000)[/java]
Processing Tweets
Step 1 – Convert the tweets to a text format.
[java]delta_txt = sapply(delta_tweets, function(t) t$getText() ) jetblue_txt = sapply(jetblue_tweets, function(t) t$getText() ) united_txt = sapply(united_tweets, function(t) t$getText() )[/java]
Step 2 – Calculate the number of tweets for each airline.
[java]noof_tweets = c(length(delta_txt), length(jetblue_txt),length(united_txt))[/java]
Step 3 – Combine the text of all these airlines
[java]airline<- c(delta_txt,jetblue_txt,united_txt)[/java]
Sentiment Analysis Application (Code)
The code below showcases how sentiment analysis is written and executed. However, before we proceed with sentiment analysis, a function needs to be defined that will calculate the sentiment score.
[java]score.sentiment = function(sentences, pos.words, neg.words, .progress='none')
{
# Parameters
# sentences: vector of text to score
# pos.words: vector of words of positive sentiment
# neg.words: vector of words of negative sentiment
# .progress: passed to laply() to control of progress bar
# create a simple array of scores with laply
scores = laply(sentences,
function(sentence, pos.words, neg.words)
{
# remove punctuation
sentence = gsub("[[:punct:]]", "", sentence)
# remove control characters
sentence = gsub("[[:cntrl:]]", "", sentence)
# remove digits?
sentence = gsub('\\d+', '', sentence)
# define error handling function when trying tolower
tryTolower = function(x)
{
# create missing value
y = NA
# tryCatch error
try_error = tryCatch(tolower(x), error=function(e) e)
# if not an error
if (!inherits(try_error, "error"))
y = tolower(x)
# result
return(y)
}
# use tryTolower with sapply
sentence = sapply(sentence, tryTolower)
# split sentence into words with str_split (stringr package)
word.list = str_split(sentence, "\\s+")
words = unlist(word.list)
# compare words to the dictionaries of positive & negative terms
pos.matches = match(words, pos.words)
neg.matches = match(words, neg.words)
# get the position of the matched term or NA
# we just want a TRUE/FALSE
pos.matches = !is.na(pos.matches)
neg.matches = !is.na(neg.matches)
# final score
score = sum(pos.matches) - sum(neg.matches)
return(score)
}, pos.words, neg.words, .progress=.progress )
# data frame with scores for each sentence
scores.df = data.frame(text=sentences, score=scores)
return(scores.df)
}[/java]
Now, we can start processing the tweets to calculate the sentiment score.
[java]scores = score.sentiment(airline, pos.words,neg.words , .progress='text')[/java]
Step 1 – Create a variable in the data frame.
[java]scores$airline = factor(rep(c("Delta", "JetBlue","United"), noof_tweets))[/java]
Step 2 – Calculate positive, negative and neutral sentiments.
[java]scores$positive <- as.numeric(scores$score >0) scores$negative <- as.numeric(scores$score <0) scores$neutral <- as.numeric(scores$score==0)[/java]
Step 3 – Split the data frame into individual datasets for each airline.
[java]delta_airline <- subset(scores, scores$airline=="Delta") jetblue_airline <- subset(scores,scores$airline=="JetBlue") united_airline <- subset(scores,scores$airline=="United")[/java]
Step 4 – Create polarity variable for each data frame.
[java]delta_airline$polarity <- ifelse(delta_airline$score >0,"positive",ifelse(delta_airline$score < 0,"negative",ifelse(delta_airline$score==0,"Neutral",0)))[/java]
[java]jetblue_airline$polarity <- ifelse(jetblue_airline$score <0,"positive",ifelse(jetblue_airline$score < 0,"negative",ifelse(jetblue_airline$score==0,"Neutral",0)))[/java]
[java]united_airline$polarity <- ifelse(united_airline$score >0,"positive",ifelse(united_airline$score < 0,"negative",ifelse(united_airline$score==0,"Neutral",0)))[/java]
Generating Graphs
After the above steps are executed, developers can go ahead and create insightful graphs. The steps below outline the process to create graphs.
Polarity Plot – Customer Sentiments (Delta Airlines)
[java]qplot(factor(polarity), data=delta_airline, geom="bar", fill=factor(polarity))+xlab("Polarity Categories") + ylab("Frequency") + ggtitle("Customer Sentiments - Delta Airlines")[/java]

The bar graph above depicts polarity, if we closely analyze the graph; it reveals that out of 5,000 twitter users, 1,100 twitter users have commented in a negative way, 2,380 users are neutral. However, 1,520 users are pretty positive about the airline.
[java]qplot(factor(score), data=delta_airline, geom="bar", fill=factor(score))+xlab("Sentiment Score") + ylab("Frequency") + ggtitle("Customer Sentiment Scores - Delta Airlines")[/java]
Customer Sentiment Scores (Delta Airlines)
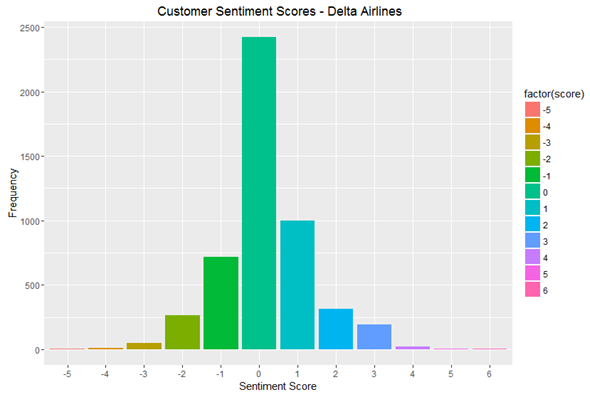
The bar graph above depicts twitter user’s sentiment score, negative score denoted by the (-) symbol, which indicates unhappiness of users with the airline, whereas the positive score denotes that users are happy with the airline. While, zero represents that twitter users are neutral.
Polarity Plot – Customer Sentiments (JetBlue Airlines)
[java]qplot(factor(polarity), data=jetblue_airline, geom="bar", fill=factor(polarity))+xlab("Polarity Categories") + ylab("Frequency") + ggtitle(" Customer Sentiments - JetBlue Airlines ")[/java]
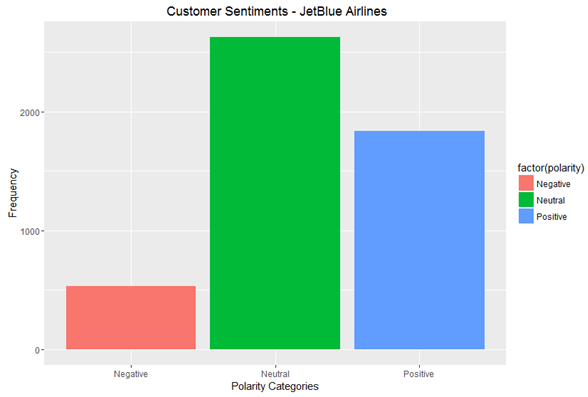
The bar graph above represents polarity. In this case, out of the 5,000 twitter users, 550 users have commented negatively, 2,700 users remain neutral, whereas 1,750 users are positive about the airline.
Customer Sentiment Scores (JetBlue Airlines)
[java]qplot(factor(score), data=jetblue_airline, geom="bar", fill=factor(score))+xlab("Sentiment Score") + ylab("Frequency") + ggtitle("Customer Sentiment Scores - JetBlue Airlines")[/java]

The bar graph above depicts twitter user’s sentiment score, negative score denoted by the (-) symbol, which indicates unhappiness with the airline, whereas the positive score denotes that users are quite happy. Whereas, zero here represents that users are neutral.
Polarity Plot – Customer Sentiments (United Airlines)
[java]qplot(factor(polarity), data=united_airline, geom="bar", fill=factor(polarity))+xlab("Polarity Categories") + ylab("Frequency") + ggtitle("Customer Sentiments - United Airlines")[/java]

The bar graph above represents polarity. In this case, out of the 5,000 twitter users, 1,350 users have commented negatively, whereas 2,200 users are neutral and remaining 1,450 users remain positive about the airline.
Customer Sentiment Scores (United Airlines)
[java]qplot(factor(score), data=united_airline, geom="bar", fill=factor(score))+xlab("Sentiment Score") + ylab("Frequency") + ggtitle("Customer Sentiment Scores - United Airlines ")[/java]

The bar graph above depicts twitter user’s sentiment score, negative score denoted by the (-) symbol indicates unhappiness of users with the airline, whereas the positive score denotes that users are quite happy. While, zero represents that users are neutral about their opinion.
Summarizing Scores
- The code below will help developers to summarize the overall positive, negative and neutral scores
[java]df = ddply(scores, c("airline"), summarise, pos_count=sum( positive ), neg_count=sum( negative ), neu_count=sum(neutral))[/java] - To put it in another way, developers can create total count by adding positive, negative and neutral sum.
[java]df$total_count = df$pos_count +df$neg_count + df$neu_count[/java]
- Additionally, developers can calculate positive, negative and neutral percentages using the below code.
[java]df$pos_prcnt_score = round( 100 * df$pos_count / df$total_count ) df$neg_prcnt_score = round( 100 * df$neg_count / df$total_count ) df$neu_prcnt_score = round( 100 * df$neu_count / df$total_count ) [/java]
Comparison Charts
Positive Comparative Analysis
Here is the code to create a positive comparison pie chart for these three airlines:
[java]attach(df) lbls <-paste(df$airline,df$pos_prcnt_score) lbls <- paste(lbls,"%",sep="") pie(pos_prcnt_score, labels = lbls, col = rainbow(length(lbls)), main = "Positive Comparative Analysis - Airlines")[/java]
The pie chart below represents positive percentage score of these airlines.

Negative Comparative Analysis
Here is the code to create a negative comparison pie chart for these three airlines:
[java]lbls <-paste(df$airline,df$neg_prcnt_score) lbls <- paste(lbls,"%",sep="") pie(neg_prcnt_score, labels = lbls, col = rainbow(length(lbls)), main = " Negative Comparative Analysis - Airlines")[/java]
The pie chart below represents negative percentage score of these three airlines.

Neutral Comparative Analysis
Here is the code to create a neutral comparison pie chart:
[java]lbls <-paste(df$airline,df$neu_prcnt_score) lbls <- paste(lbls,"%",sep="") pie(neu_prcnt_score, labels = lbls, col = rainbow(length(lbls)), main = "Neutral Comparative Analysis - Airlines")[/java]
The pie chart below represents neutral percentage score of these three airlines.

Conclusion
As can be seen, sentiment analysis enables enterprises to understand consumer sentiments in relation to specific products/services. Moreover, these insights could be used to improve their products and services by gauging consumers’ comments and feedback using sentiment analysis. In the long run, sentiment analysis, if implemented the right way can aid business enterprises in improving the overall consumer experience, enhance brand image and propel business growth.
IT Consulting Services
At Evoke, we enable businesses augment data science to solve day-to-day business problems and make informed decisions by applying data science. With more than a decade’s experience in software development and deployment, we provide IT solutions that decrease your company’s expenditures, while increasing your bottom line. And our highly trained, dedicated teams of IT engineers remain available to support you 24/7.
Call Evoke today at +1 (937) 202-4161 (select Option 2 for Sales) or contact us online to learn more about how we can help your company take steps today toward greater digital maturity and profitability.
Author
 |
Veera Raghava Reddy was working as a lead data scientist at Evoke Technologies. He was part of the Data Science COE at Evoke. Raghava has more than 7 years of experience in the field of IT and Data Science with strong technical expertise in R, Python, SPSS, and Tableau. |


34 Comments
Please do you know of a way to install Sentiment Package of R 3.3.0?
There is no direct sentiment package in R. We have to install a list of packages as mentioned in the blog post to work on Sentiment algorithm.
We did the same without ‘R’ long time back (9 years back) for iPhone Launch with Apple Inc. and for many more corporates and were able to produce effective outputs as expected.
The same procedures, but did them all using JAVA. Now we use R language, but does not make any difference.
Hi There
Sounds Good.
But does this filters out and produces results for something like …..”Hooo…God Dame Good but ruined by life to the core and beeps my money to retain my life back, I hate giving this up”
The above statement is about a product…
While reading the above statement sounds positive but actually posted for negative…
How does a computer language/program analyse whether this statement is a POSITIVE or a NEGATIVE one? It is purely left with the senses that a human takes in…
I may be wrong, but can you explain this in detail and how you will prove for sure that this statement is negative.
Analyze the following statements positive or negative ? using R language
“Wooooooooo… Toooooo Good… People please go buy this product and have FUN in LIFE”
“Man this product is Toooooooo Goooooood, enjoy buying… and feel the pain as I had….”
Let see how good Computers are!!!
well my code says its negative…..yay
posText posText posText negText negText negText pos.words = c(posText, ‘upgrade’)
Error: object ‘posText’ not found
> neg.words = c(negText, ‘wtf’, ‘wait’, ‘waiting’,’epicfail’, ‘mechanical’)
Error: object ‘negText’ not found
api_key <- "yourconsumerkey" Where will i find the consumerkey??
api_secret <- "yourconsumersecret" where will i find consumersecret??
access_token <- "consumeraccess token" where will i find consumeraccess token??
access_token_secret <- "consumer access secret token" where will i find consumer access secret token
Hello Ashok,
You need to sign-up for twitter Search API to get the above keys.
Best Regards,
Raghava
how do u match positive and negative dictionary with rows in csv file, with one row at a time? and add scores
Hello Ruchir,
From each row extract positive and negative words and compare with the dictionary of lexicon words and calculate the scores by utilizing sentiment algorithm.
Please go through the above code, which will help you get better insights on the solution.
Regards,
Raghava
Hi Veera,
I am doing some sentiment analysis from CSV file. I am able to get overall word cloud, and graphs for the comments.
I have addtional two columns one is for department and the other location in the same file. How could i go about segregating it by either of these two.
Any suggestions/thoughts?
Regards,
Renato.
Hi Renato,
Utilize the Aggregate function in R by department and location wise. This should help you out.
Regards,
Raghava
Hi Raghava,
I tried the same. After creating my TDM , i created a dataframe “frequentKeywordDF”, and used the below code to get the data.
eachdepartment <- aggregate(x= frequentKeywordDF, by = list(keywords$department), FUN = length)
I get this error.
Error in aggregate.data.frame(x = frequentKeywordDF, by = list(keywords$department), :
arguments must have same length.
Any suggestions.
Regards,
Renato.
Hello Renato,
I would suggest you to undertake some R&D to resolve the above issue, as I am not aware of the data/variables that you are using. There are quite a few solutions available on the Stack Overflow website.
Additionally, you can also use another function ‘dplyr’ available in R.
Hopefully this should resolve the issue.
Best Regards,
Raghava
Hi Veera,
Incase this is a duplicate comment please ignore as i am unable to see the earlier one.
Could you share your thoughts on how about segregating sentiment analysis from CSV file that use there columns, Department, Location and Comments. I am able to get the overall analysis using only the comments section. Is there a way this could be broken down by the department and location?
Regards,
Renato.
Hi,
I did this analysis for a CSV file of a survey response comments.
It has categorized 99% of the responses as neutral when they are clearly positive or negative.
Is this because of the dictionary? Should I use some other dictionary of positive and negative words?
Hello Abirami,
It is quite likely that the comments include both positive and negative words, hence the algorithm is calculating a score based on the number of positive and negative words. It would be great if you could share one or two comments so that I can analyze.
Best Regards,
Raghava
i tried to run the code and I get this error !! could you please help me with it and very great job thanks
the error is
Error in .fun(piece, …) : object ‘neg.words’ not found
Hello Hiba,
Could you please recheck if the below lines of code are included in your program and are executing, when the program is being run. Hopefully, this should resolve your issue.
negText <- read.delim("…/negative-words.txt", header=FALSE, stringsAsFactors=FALSE)
negText <- negText$V1
negText <- unlist(lapply(negText, function(x) { str_split(x, "\n") }))
neg.words = c(negText, 'wtf', 'wait', 'waiting','epicfail', 'mechanical')
Let me know if this works.
Best Regards,
Raghava
thank u very much
hi sir, I am considering stocktwits website for doing sentimental analysis and the market behavior impact of messages, but there is no api for this website ,so how can i download the messages for analysis
Hi Vishnu,
All you need to do is register on twitter API, you will receive four keys as mentioned in the blog. Simply select @StockTwits twitter handle and apply the above algorithm to perform sentiment analysis.
Regards,
Raghava
Thank you for your swift reply.
I wish to make a dataframe out of json files in a directory. json files are in thousands say 45k files.
then I have to do sentiment analysis on them. my ultimate goal is to do sentiment analysis on those json files using r. any suggestions?
Use the forloop function.
hi
thanks for the explanation. However, I still have a question. have u used Naïve Bayes (NB) for sentiment classification? And in step 2 – Calculate positive, negative and neutral sentiments.
scores$negative 0)
this should be <0 or it's okay??
thank u very much
I haven’t used Naive Bayes (NB) for sentiment classification.
Yes, if calculated sentiment score is less than 0, considering negative sentiment.
Error in factor(polarity) + xlab(“polarity Catogeries”) + ylab(“frequency”) :
non-numeric argument to binary operator
i am getting this error please resolve this
Siddharth, it appears that instead of using a numeric variable in polarity, you are using text. Try using a numeric variable.
Hello Mr. Reddy
I am working on “Tweet sentiment analysis for cellular network service providers using machine learning algorithms”.
I had fetched 5000 tweets of each cellular service provider i.e. 5000 of Jio and 5000 of Airtel . Now i am not deciding what would be the next step. could you please tell me how to fetch the feature points from data I means how to identify the attributes which decide the overall sentiment score. if in case u want me to send the dataset i can send it to u.
Hello Mr Reddy,
How did you remove the error in the line: setup_twitter_oauth(api_key,api_secret,access_token,access_token_secret)
1] “Using direct authentication”
Error in check_twitter_oauth() : OAuth authentication error:
This most likely means that you have incorrectly called setup_twitter_oauth()
hi i am getting the wrong sentiment scores for example if the tweet has 1 positive and 1 negative word the score that is displayed is 2.
Hi sir,
Rose from kerala…..Can you explain how can we interpret the pie chart.As its not showing 100%.
like…..
in positive analysis : 31% of positive comments are for Delta….
is it 31% of positive text that we have downloaded??? —– And i have tried this tooo….but the total is not matching….
can you explain the logic behind it….
As i am stuck in my research part….can you reply it ASAP…..
Regards,
Rose
Mr. Reddy…..can you reply to my doubt …..as its urgent for my project…..
Let’s take a look at the interpretation: In the comment data set of Delta Airline, 31% of user comments are positive, 21% comments are negative and 48% are neutral (you can refer to the other pie charts for details), giving us a sum of 100%. Whereas, in the “Positive Comparative Analysis” pie chart, 28.8% of the total comments are positive for Delta Airline.